Conversational AI for Database Access: Build or Buy?
Download this infographic >>
When it comes to creating digital conversational experiences, intent classifiers are one of the most popular ways to build out systems geared towards answering customer and user questions, seamlessly.
With many intent classification systems available on the market, developers can leverage a natural language understanding (NLU) platform or machine learning services to build out technologies like chatbots and virtual assistants. We go into greater detail about how intent classifiers work in this post about current conversational AI technology.
Intent classification systems are great tools for solving a variety of use cases in which there’s a manageable volume of intents and entities. However, when it comes to solving the growing problem of database access, building an intent classifier to provide natural language database querying capabilities isn’t the best option.
Here at Chata, we believe conversational AI can revolutionize the way leaders across all industries leverage their data throughout their organization. With the right conversational AI system, anyone can query their data without needing to learn SQL.
Data is more important than ever for decision making and, therefore, data access needs to be democratized so that every employee is empowered to make data-driven decisions on a regular basis.
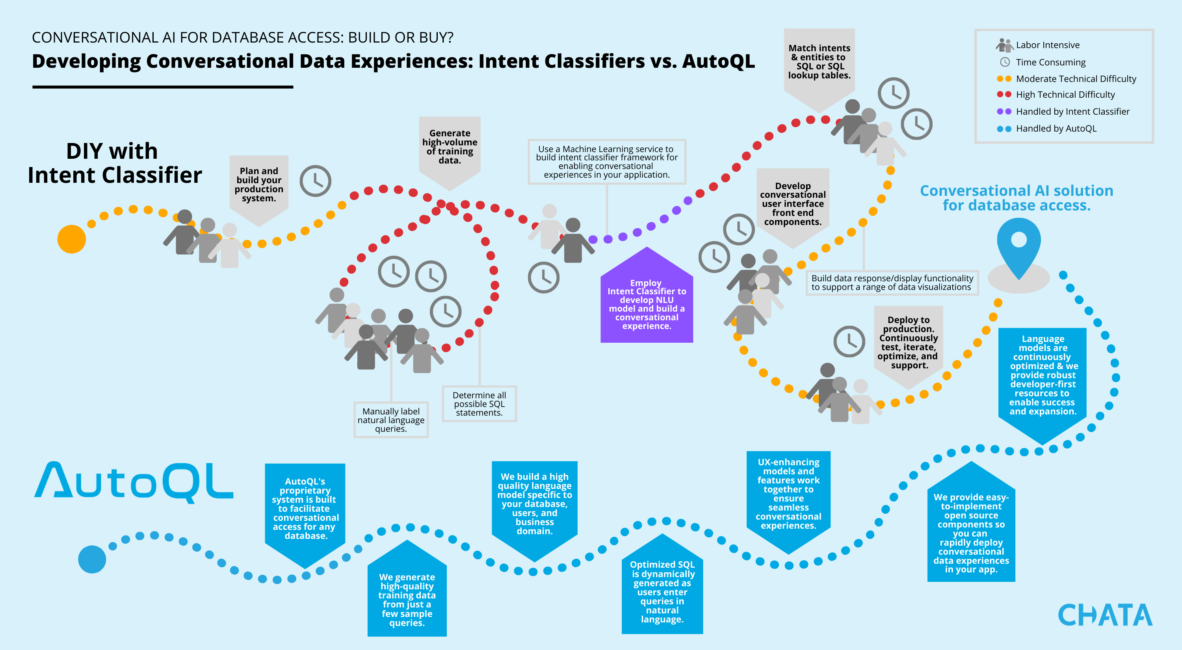
For software providers, offering cutting-edge database access capabilities can launch their solution ahead of their competition, but building out a robust system takes expensive engineering time and extensive manual labor, especially in the area of training data generation. The infographic above outlines what it would take to build out a system for conversational database access using an intent classifier, which is only one small component of such a system.
Our flagship solution, AutoQL, is a complete system that’s ready to integrate with any enterprise-grade database. At the heart of AutoQL is our proprietary text-to-SQL translation technology.
Rather than classifying intents, AutoQL understands meaning in natural language queries and dynamically generates SQL statements that run on the database and return data in comprehensive visualizations in seconds. The system is capable of dynamically producing optimal SQL statements from natural language, including multi-table joining SQL, to provide comprehensive coverage of the entire database.
Text-to-SQL technology represents a new frontier for database access and can unleash the value of data that’s often siloed in relational databases. One of the major limitations of leveraging intent classification for this job is that the manual work surrounding the development of the solution is labor intensive and time consuming, especially when it comes to generating training data.
Behind a great text-to-SQL system built for enterprise-grade databases is a high volume of excellent training data, which we also take care of through the AutoQL integration process.
As Aerin Kim, Senior Research Engineer at Microsoft, notes: “The number of columns in WikiSQL dataset* is usually 5–7 and the number of rows is about 10. Meanwhile, a typical enterprise table has 30–40 columns and millions of rows in a single table.” This means that the system needs to “learn” on far more training data to understand the complexity of these types of databases.
Through automating the training data generation process, we are able to customize our machine learning models to unique databases very quickly. With high-quality training data, AutoQL is able to understand both the nuances of human language (including business domain-specific terminology and unique words for items in the database) as well as the structure and complexity of an enterprise-grade database.
With text-to-SQL solutions for database access, anyone––from front-line workers on the sales floor, to intermediate managers and C-suite executives––can access their data intuitively and discover unique insights faster than ever with data at their fingertips.
Learn more in our white paper: Next-Generation Conversational AI for Database Access: The Technology Behind AutoQL
* WikiSQL is a supervised text-to-SQL dataset that serves as a benchmark for the success of converting natural language into a language like SQL that computers can readily understand.