Topics

See How Chata.ai Helps Teams Act Faster
See How Chata.ai Helps Teams Act Faster
How Deterministic AI Works: Built to Be Verified

Published
8 min read
Topics:
Reliable AI

Table of Contents
Most AI systems are built to seem accurate. Deterministic AI is built to prove it — every single time, on every single query, with a full audit trail your compliance team can actually use.
A 95% accurate AI sounds impressive — until you run a 10-step workflow and your accuracy drops to 59.9%. That's not a risk calculation. That's cold math.
Compound it: if every step in your analytics workflow carries a 95% accuracy rate, you multiply those probabilities together. Five steps: 77%. Eight steps: 66%. Ten steps: just under 60%. At that point, you're not running analysis — you're playing odds.
This is the accuracy problem that nobody talks about when they demo an AI tool in a controlled environment with a carefully chosen question. But it's the problem that surfaces immediately when your CFO asks why the revenue figure in this morning's report doesn't match last week's number — and the AI tells you both are correct.
The architectural choice that determines whether your AI compounds error or eliminates it isn't a configuration setting. It's a foundational design decision made before a single line of your data was ever touched.
Not All AI Is Built the Same: Probabilistic vs. Deterministic
One guesses the most likely answer. One executes exact logic. Here's why that distinction matters.
The AI tools most people encounter — the large language models behind chat interfaces, copilots, and generative analytics features — are probabilistic systems. They were built to predict: given a body of text, what response is most likely to be helpful or accurate? That capability is extraordinary for drafting emails, summarizing documents, or explaining a concept in plain language.
However, probabilistic prediction is a fundamentally different task than data retrieval. When you ask your analytics tool what total revenue was in Q3 compared to Q2, you don't want the most statistically likely answer. You want the correct answer. Every time. Without qualification.
How Determinstic AI Actually Works
The term "deterministic" gets used loosely. In engineering, it has a precise meaning: given the same input, a deterministic system will always produce the same output. No variation. No inference. No probability distribution over possible answers.
Achieving that in a natural language analytics system requires more than tuning a language model. It requires a different architecture entirely — one designed not to generate plausible-sounding text, but to translate a human question into an exact database operation and return the precise result.
Here's how that architecture is structured:
Natural Language Question → Query Decomposition → Database Execution → Auditable Output
Chata.ai's platform is built on a four-stage pipeline, fed by two proprietary inputs that set it apart from anything built on a general-purpose model.
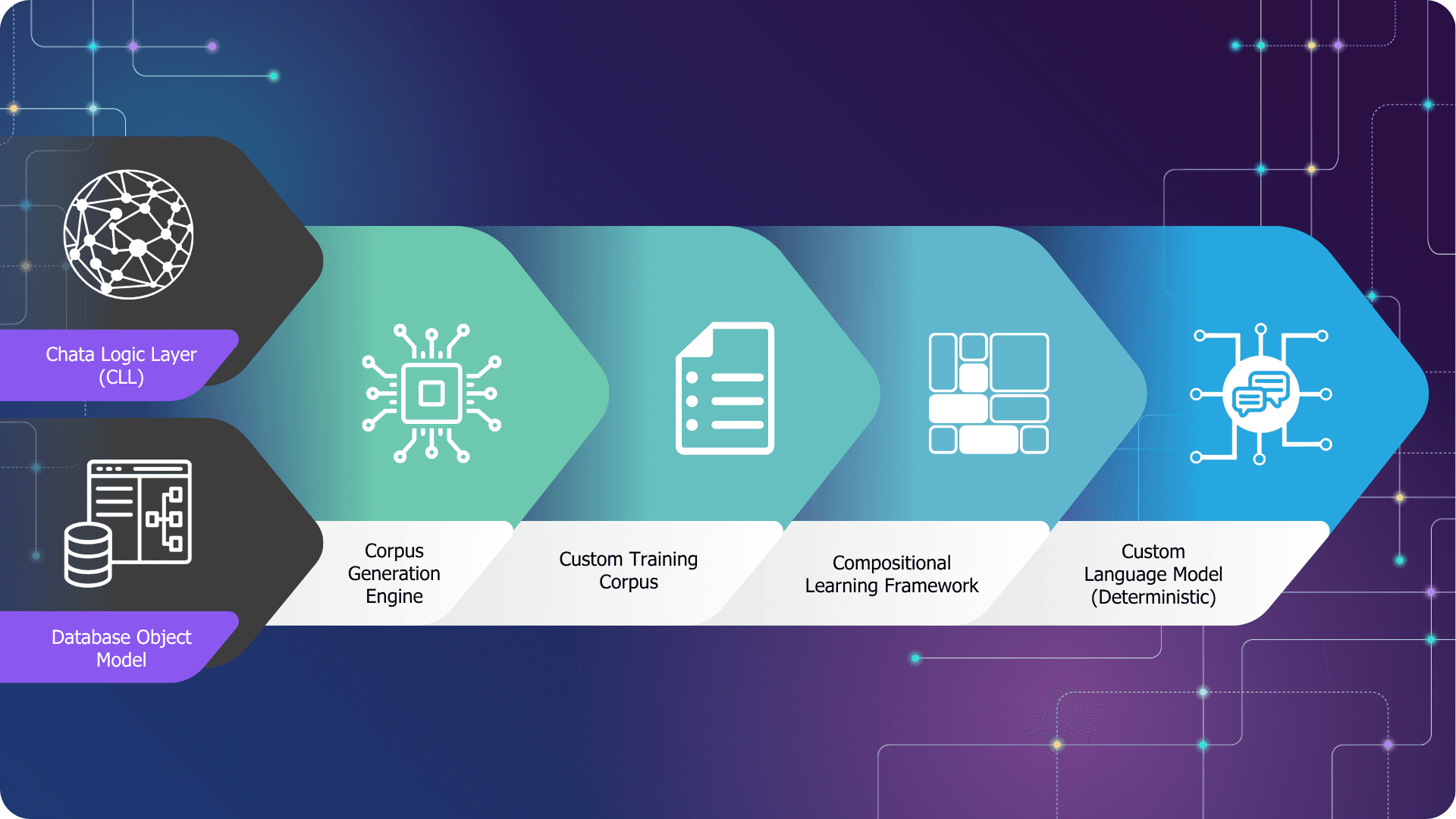
The two inputs
Everything starts with what goes into the system, not what the system already knows. Two inputs feed the pipeline: the Chata Logic Layer (CLL) — Chata.ai's proprietary business language semantics, the rules that govern how your organization talks about its data — and the Database Object Model, your schema, data types, table relationships, and structure.
This is the first and most important distinction: the system learns the shape of your data environment, not the data itself. Your records never enter the training process.
Stage 1: Corpus Generation Engine
The two inputs feed a Corpus Generation Engine, which constructs a custom training dataset from your schema and business logic. This isn't general internet data cleaned and filtered. It's a purpose-built corpus derived entirely from your specific environment — your field names, your relationships, your terminology.
Stage 2: Custom Training Corpus
The output of the generation engine is a Custom Training Corpus — a structured dataset that reflects exactly how questions map to queryable structures in your database. This corpus is what the model trains on. It is unique to every customer deployment.
Stage 3: Compositional Learning Framework
When a business user asks a question in plain English, the Compositional Learning Framework breaks it into its component parts and reassembles them into a precise database query. This is compositional reasoning, not probabilistic inference. There's no guessing about intent, no interpretation drift based on phrasing variation, no temperature setting producing slightly different outputs on different days.
Stage 4: Custom Language Model (Deterministic)
The result is a Custom Language Model that is structurally separate from any general-purpose LLM — not a fine-tune, not a wrapper, not a retrieval layer bolted onto a foundation model. It executes standard logic against your actual data and returns an output with a complete, traceable audit trail.
That traceability isn't a compliance add-on. It's a natural consequence of how the system is built: every answer can be traced back to the query logic that produced it.
CPU-Based Execution
The resulting query runs as standard SQL on a CPU. There's no neural network involved in producing the final answer. The database returns exactly what the query requests. If you ask the same question tomorrow, the same query runs and the same logic executes against your current data. The output is determined by your data, not by the model's most recent probability distribution.
Key point: The model trains on your schema, not your data. Your data never enters the training process — and no inference engine is involved in producing the final number.
The accuracy compound problem disappears in this architecture. Not because each step is more accurate, but because each step is exact. There's no probability to compound.
Accuracy Over a 10-Step Workflow
Probabilistic AI (95%/step) | Deterministic AI | |
|---|---|---|
After 1 step | 95% | 100% |
After 5 steps | 77% | 100% |
After 10 steps | 59.9% | 100% |
Deterministic execution doesn't reduce error — it eliminates the error surface entirely. Each step returns an exact result.

Verified by Independent Analysts: What Info-Tech Research Found
Third-party validation matters — particularly when the claims involve accuracy.
Info-Tech Research Group — operating through their SoftwareReviews division — published an independent evaluation of Chata.ai's approach. Their analysis focused specifically on whether the deterministic architecture delivers on its core promise: consistent, auditable, hallucination-free analytics output.
"Chata.ai's deterministic approach to AI-powered analytics addresses a fundamental limitation of generative AI in structured data environments — the inability to guarantee output consistency and provide a verifiable audit trail."
Source: SoftwareReviews / Info-Tech Research Group — "Chata.ai: Deterministic AI That Does Not Lie"
Finding: The evaluation identified chata.ai's schema-based training process as a key architectural differentiator — specifically noting that the training corpus is derived from business logic and data structure, not from the data itself, which eliminates privacy exposure inherent in models that train on live enterprise data.
Key Takeaway: Info-Tech highlighted that the deterministic model is particularly well-suited for regulated industries where compliance teams require answers they can trace end-to-end — not just outputs they can audit after the fact, but a system where the derivation is auditable by design.
Independent validation like this matters when you're making procurement decisions that will affect compliance posture, audit readiness, and the trust your teams place in the numbers they act on.
Who Deterministic AI Is Built For
Precision instrument, not general reasoning engine — and that distinction is worth being honest about.
Deterministic AI in analytics isn't a universal replacement for every AI capability. It's a precision instrument designed for a specific and high-stakes job: returning exact, auditable answers from structured enterprise data.
Understanding where deterministic AI fits — and where it doesn't — is part of using it intelligently. The organizations that get the most value from it know exactly why they chose it.
Right fit:
Financial services and regulated analytics where every output must be explainable to auditors
Enterprise reporting where consistency across queries is non-negotiable
Business intelligence teams that need self-serve access without SQL — and without introducing governance risk
Compliance-sensitive workflows where hallucination risk carries legal exposure
Organizations with well-structured data who want that structure respected, not ignored
Not the right fit:
Open-ended reasoning tasks where the question doesn't have a single correct answer
Macroeconomic prediction or scenario modeling that requires inference beyond existing data
Unstructured data exploration — documents, emails, free-text fields — without a defined schema
Creative content generation or synthesis tasks where variation is a feature, not a risk
The organizations that evaluate deterministic AI honestly — rather than looking for a tool that claims to do everything — tend to deploy it faster and get cleaner outcomes. If your core analytics problem involves structured enterprise data and a need for trusted numbers, the architectural fit is direct. If your problem is something else, a different tool may serve you better, and we'd rather you know that upfront.
If you're still working out whether your current analytics environment has a structural trust problem, the patterns described in 5 Signs Your Enterprise Analytics Needs a Deterministic AI Platform are a useful diagnostic.
See the Deterministic Architecture in Action
The most direct way to evaluate a deterministic AI system isn't a slide deck. It's asking the same question twice and checking that the answers match — then tracing exactly how they were derived. See how it works:
Topics
See How Chata.ai Helps Teams Act Faster
How Deterministic AI Works: Built to Be Verified
Published
8 min read
Topics:
Reliable AI
Table of Contents
Most AI systems are built to seem accurate. Deterministic AI is built to prove it — every single time, on every single query, with a full audit trail your compliance team can actually use.
A 95% accurate AI sounds impressive — until you run a 10-step workflow and your accuracy drops to 59.9%. That's not a risk calculation. That's cold math.
Compound it: if every step in your analytics workflow carries a 95% accuracy rate, you multiply those probabilities together. Five steps: 77%. Eight steps: 66%. Ten steps: just under 60%. At that point, you're not running analysis — you're playing odds.
This is the accuracy problem that nobody talks about when they demo an AI tool in a controlled environment with a carefully chosen question. But it's the problem that surfaces immediately when your CFO asks why the revenue figure in this morning's report doesn't match last week's number — and the AI tells you both are correct.
The architectural choice that determines whether your AI compounds error or eliminates it isn't a configuration setting. It's a foundational design decision made before a single line of your data was ever touched.
Not All AI Is Built the Same: Probabilistic vs. Deterministic
One guesses the most likely answer. One executes exact logic. Here's why that distinction matters.
The AI tools most people encounter — the large language models behind chat interfaces, copilots, and generative analytics features — are probabilistic systems. They were built to predict: given a body of text, what response is most likely to be helpful or accurate? That capability is extraordinary for drafting emails, summarizing documents, or explaining a concept in plain language.
However, probabilistic prediction is a fundamentally different task than data retrieval. When you ask your analytics tool what total revenue was in Q3 compared to Q2, you don't want the most statistically likely answer. You want the correct answer. Every time. Without qualification.
How Determinstic AI Actually Works
The term "deterministic" gets used loosely. In engineering, it has a precise meaning: given the same input, a deterministic system will always produce the same output. No variation. No inference. No probability distribution over possible answers.
Achieving that in a natural language analytics system requires more than tuning a language model. It requires a different architecture entirely — one designed not to generate plausible-sounding text, but to translate a human question into an exact database operation and return the precise result.
Here's how that architecture is structured:
Natural Language Question → Query Decomposition → Database Execution → Auditable Output
Chata.ai's platform is built on a four-stage pipeline, fed by two proprietary inputs that set it apart from anything built on a general-purpose model.
The two inputs
Everything starts with what goes into the system, not what the system already knows. Two inputs feed the pipeline: the Chata Logic Layer (CLL) — Chata.ai's proprietary business language semantics, the rules that govern how your organization talks about its data — and the Database Object Model, your schema, data types, table relationships, and structure.
This is the first and most important distinction: the system learns the shape of your data environment, not the data itself. Your records never enter the training process.
Stage 1: Corpus Generation Engine
The two inputs feed a Corpus Generation Engine, which constructs a custom training dataset from your schema and business logic. This isn't general internet data cleaned and filtered. It's a purpose-built corpus derived entirely from your specific environment — your field names, your relationships, your terminology.
Stage 2: Custom Training Corpus
The output of the generation engine is a Custom Training Corpus — a structured dataset that reflects exactly how questions map to queryable structures in your database. This corpus is what the model trains on. It is unique to every customer deployment.
Stage 3: Compositional Learning Framework
When a business user asks a question in plain English, the Compositional Learning Framework breaks it into its component parts and reassembles them into a precise database query. This is compositional reasoning, not probabilistic inference. There's no guessing about intent, no interpretation drift based on phrasing variation, no temperature setting producing slightly different outputs on different days.
Stage 4: Custom Language Model (Deterministic)
The result is a Custom Language Model that is structurally separate from any general-purpose LLM — not a fine-tune, not a wrapper, not a retrieval layer bolted onto a foundation model. It executes standard logic against your actual data and returns an output with a complete, traceable audit trail.
That traceability isn't a compliance add-on. It's a natural consequence of how the system is built: every answer can be traced back to the query logic that produced it.
CPU-Based Execution
The resulting query runs as standard SQL on a CPU. There's no neural network involved in producing the final answer. The database returns exactly what the query requests. If you ask the same question tomorrow, the same query runs and the same logic executes against your current data. The output is determined by your data, not by the model's most recent probability distribution.
Key point: The model trains on your schema, not your data. Your data never enters the training process — and no inference engine is involved in producing the final number.
The accuracy compound problem disappears in this architecture. Not because each step is more accurate, but because each step is exact. There's no probability to compound.
Accuracy Over a 10-Step Workflow
Probabilistic AI (95%/step) | Deterministic AI | |
|---|---|---|
After 1 step | 95% | 100% |
After 5 steps | 77% | 100% |
After 10 steps | 59.9% | 100% |
Deterministic execution doesn't reduce error — it eliminates the error surface entirely. Each step returns an exact result.
Verified by Independent Analysts: What Info-Tech Research Found
Third-party validation matters — particularly when the claims involve accuracy.
Info-Tech Research Group — operating through their SoftwareReviews division — published an independent evaluation of Chata.ai's approach. Their analysis focused specifically on whether the deterministic architecture delivers on its core promise: consistent, auditable, hallucination-free analytics output.
"Chata.ai's deterministic approach to AI-powered analytics addresses a fundamental limitation of generative AI in structured data environments — the inability to guarantee output consistency and provide a verifiable audit trail."
Source: SoftwareReviews / Info-Tech Research Group — "Chata.ai: Deterministic AI That Does Not Lie"
Finding: The evaluation identified chata.ai's schema-based training process as a key architectural differentiator — specifically noting that the training corpus is derived from business logic and data structure, not from the data itself, which eliminates privacy exposure inherent in models that train on live enterprise data.
Key Takeaway: Info-Tech highlighted that the deterministic model is particularly well-suited for regulated industries where compliance teams require answers they can trace end-to-end — not just outputs they can audit after the fact, but a system where the derivation is auditable by design.
Independent validation like this matters when you're making procurement decisions that will affect compliance posture, audit readiness, and the trust your teams place in the numbers they act on.
Who Deterministic AI Is Built For
Precision instrument, not general reasoning engine — and that distinction is worth being honest about.
Deterministic AI in analytics isn't a universal replacement for every AI capability. It's a precision instrument designed for a specific and high-stakes job: returning exact, auditable answers from structured enterprise data.
Understanding where deterministic AI fits — and where it doesn't — is part of using it intelligently. The organizations that get the most value from it know exactly why they chose it.
Right fit:
Financial services and regulated analytics where every output must be explainable to auditors
Enterprise reporting where consistency across queries is non-negotiable
Business intelligence teams that need self-serve access without SQL — and without introducing governance risk
Compliance-sensitive workflows where hallucination risk carries legal exposure
Organizations with well-structured data who want that structure respected, not ignored
Not the right fit:
Open-ended reasoning tasks where the question doesn't have a single correct answer
Macroeconomic prediction or scenario modeling that requires inference beyond existing data
Unstructured data exploration — documents, emails, free-text fields — without a defined schema
Creative content generation or synthesis tasks where variation is a feature, not a risk
The organizations that evaluate deterministic AI honestly — rather than looking for a tool that claims to do everything — tend to deploy it faster and get cleaner outcomes. If your core analytics problem involves structured enterprise data and a need for trusted numbers, the architectural fit is direct. If your problem is something else, a different tool may serve you better, and we'd rather you know that upfront.
If you're still working out whether your current analytics environment has a structural trust problem, the patterns described in 5 Signs Your Enterprise Analytics Needs a Deterministic AI Platform are a useful diagnostic.
See the Deterministic Architecture in Action
The most direct way to evaluate a deterministic AI system isn't a slide deck. It's asking the same question twice and checking that the answers match — then tracing exactly how they were derived. See how it works:
More Updates



