Topics

See How Chata.ai Helps Teams Act Faster
See How Chata.ai Helps Teams Act Faster
Hallucination-Free AI Analytics Tools: Is It Possible and How Does It Work?

Published
5 min read
Topics:
Reliable AI

Table of Contents
Every AI vendor claims accuracy. Is truly hallucination-free AI analytics actually achievable — or just a marketing promise?
The industry's answer to this has been more guardrails. Better prompts. Smarter validators. However, these approaches treat a symptom, not the disease. The hallucination problem in data analytics isn't a tuning problem — it's an architectural one.
This post explains why hallucination is baked into how most AI analytics tools are built, what a genuinely hallucination-free system looks like under the hood, and what to look for when you're evaluating platforms.
A Stanford RegLab study found that leading legal-AI RAG tools, built by major vendors, still hallucinated in 17–33% of queries — a pattern that shows up whenever RAG is treated as a hallucination "fix" rather than a risk-reducer, regardless of domain.
Why Do AI Analytics Tools Hallucinate?
The short answer: because they were never designed to do math. They were designed to generate text.
Large Language Models are probabilistic next-token predictors. Given a sequence of text, they predict what word is most likely to come next — based on patterns in their training data. This works extraordinarily well for summarization, drafting, and conversation. It is a fundamental liability for data analytics.
When you ask an LLM a data question, it doesn't query your database. It generates a string of text that looks like an answer to a data question. The number it returns is the most statistically plausible number to appear in that context — not a value retrieved from your actual data.
This is the "confident wrong answer" failure mode. The model doesn't know it's wrong. It has no mechanism for knowing. It is doing exactly what it was built to do: generate plausible-sounding output.
This failure mode is especially dangerous in analytics because the outputs are numbers, and numbers look authoritative. A VP of Finance doesn't scrutinize a revenue figure the way they'd scrutinize a paragraph of prose. If the number is formatted correctly and fits the expected range, it gets used.
The IBM Institute for Business Value found that 96% of AI leaders say trustworthy, explainable AI is critical to their organizations — but fewer than half have actually implemented it. That gap exists precisely because the platforms most organizations deploy are probabilistic at their core, and no amount of post-hoc explainability tooling changes what's happening underneath.
The critical distinction is this: in a standard LLM-powered analytics tool, the AI generates the final number. There is no query. There is no audit trail. There is no way to verify where the answer came from — because it didn't come from your data. It came from a model's learned statistical associations.
How Is Deterministic AI Different?
Deterministic AI means the same input always produces the same output. In the context of data analytics, it means the AI never generates a data value — it generates a precise database query, which the database then executes. The data source is the source of truth. The model is a translator, not an oracle.
Here's the architectural difference, side by side:
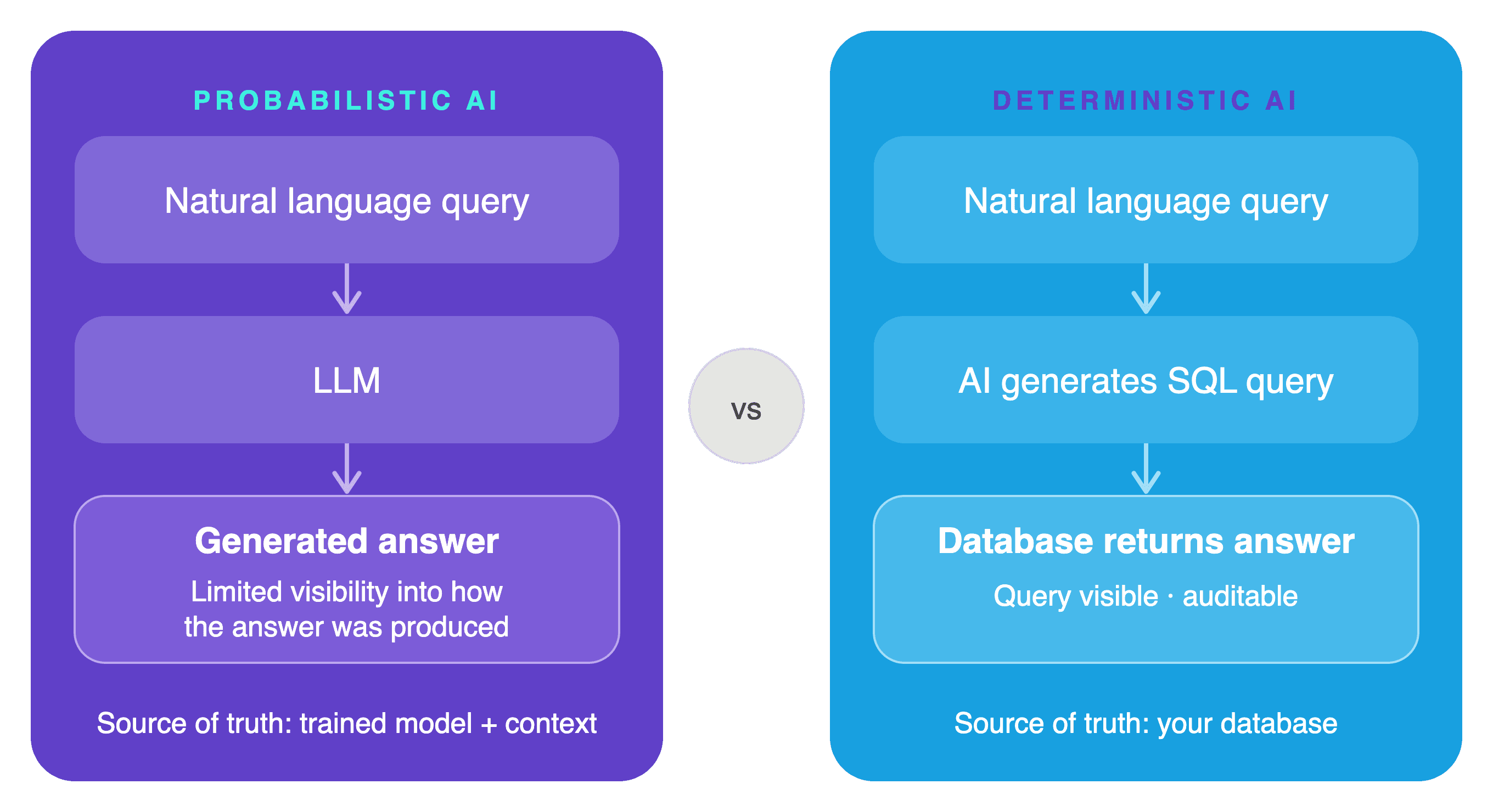
Probabilistic AI pipeline: Natural language input → LLM → Generated answer (text)
Deterministic AI pipeline: Natural language input → Query language (SQL or equivalent) → Database → Verified result
In the deterministic model, the AI's job is translation: convert the user's natural language question into a precise, executable query. That query is then run against the actual database. The result is a real data value retrieved from a real data source. The model never generates a number. It generates the instructions to retrieve a number.
This distinction matters for three reasons. First, it eliminates the hallucination vector entirely — the database returns whatever the database contains, and databases don't fabricate values. Second, it makes every answer auditable — the generated query is inspectable, shareable, and repeatable. Third, it makes the system consistent — the same question asked twice returns the same answer (assuming the underlying data hasn't changed), which is a property probabilistic systems cannot guarantee.
Deterministic AI in Analytics: When Accuracy Matters Most explores this architectural distinction in depth, including why it's becoming a compliance requirement rather than just a design preference in regulated industries.
This is the architectural principle behind AutoQL — Chata.ai's core analytics engine. AutoQL translates natural language questions into precise database queries, executes them against your connected data sources, and returns verified results. It doesn't generate answers. It generates queries. The distinction is the product.
What to Look for in a Hallucination-Free AI Analytics Platform
Not all AI analytics platforms are architecturally equivalent, and most marketing materials won't tell you which kind you're looking at. The single most important evaluation criterion is whether the system generates the answer (probabilistic) or generates the query (deterministic). Everything else — UI, integrations, visualization options — is secondary to this architectural distinction.
When evaluating a platform, ask these five questions:
Does the system generate a query or an answer? Ask the vendor to show you what the system produces internally before it returns a result.
Is the generated query visible and auditable? A query you can read is a query you can verify. If the system doesn't surface its query to the user, ask why.
Can it connect to your specific database or data warehouse natively? Deterministic AI requires tight schema-level integration. If the system connects to everything generically, it's probably working probabilistically.
Does it maintain consistent output for the same input? Ask the same question twice. The answers should be identical (if the underlying data hasn't changed). Probabilistic systems will often vary.
Can it handle multi-table, cross-system queries without guessing? Complex analytical queries that span multiple tables or systems are where probabilistic systems break down most visibly. Push the system here.
Chata.ai's Natural Language Queries feature is built on this deterministic foundation — every query is traceable, every result is verifiable, and the generated query is surfaced to users with a single click.

The Audit Trail Requirement — Why CTOs Can't Deploy Black Boxes
In regulated industries — financial services, logistics, defense, healthcare — explainability is not a feature request. It is a procurement condition.
A system that cannot explain how it arrived at a number cannot be deployed in environments where that number drives decisions. This is increasingly not a philosophical position but a regulatory one. Deloitte AI Institute (2024) found that 73% of enterprise AI deployments in regulated industries require full decision traceability as a procurement condition.
The "show your work" principle — familiar from school mathematics — has a direct enterprise equivalent: show the query. When Chata.ai's AutoQL returns an answer, the generated query is available to any user with a single click. That query is a complete, human-readable record of exactly how the result was derived: which tables were accessed, which filters were applied, what aggregations were performed. It functions as an audit log by design, not as an afterthought.
This satisfies several distinct stakeholder concerns that typically surface during enterprise procurement. InfoSec teams can verify that the system is querying only the data it's authorized to access. Legal and compliance teams can demonstrate to auditors how any given figure was derived. Data architects can review query logic to ensure it aligns with business definitions and data governance policies.
The alternative — deploying a system that generates answers without generating queries — means accepting that some percentage of decisions in your organization will be made on fabricated data, with no mechanism to identify which ones. In a 250-query workday at a 4% error rate, that's 10 decisions per day made on hallucinated figures. Over a fiscal quarter, that's potentially hundreds of compounding errors with no audit trail to surface them.
For teams building on the AutoQL architecture, Chata.ai's Architecture & Deployment page covers how the query generation and execution pipeline is structured, and how it integrates with existing data governance frameworks.
What Independent Research Says
Third-party validation matters when a vendor is making strong accuracy claims. The Info-Tech Research Group / SoftwareReviews May 2026 evaluation of Chata.ai's architecture provides independent analysis worth noting for buyers in this category.
The evaluation found that Chata.ai's deterministic approach "addresses a fundamental limitation of generative AI in structured data environments — the inability to guarantee output consistency and provide a verifiable audit trail." This mirrors the architectural argument above, from an independent research perspective.
Two additional findings from the evaluation are worth surfacing for enterprise buyers:
Schema-based training, not data-based. Chata.ai's models train on schema structure rather than on live enterprise data. This eliminates the privacy exposure inherent in platforms that train on actual organizational data — a distinction that matters significantly for regulated industries and for organizations subject to data residency requirements.
CPU-based inference. Chata.ai's deterministic inference runs on CPU rather than GPU. This removes the cost curve that makes LLM-based analytics tools prohibitively expensive at enterprise scale — where query volume can run into the millions per month.
FAQ
Can AI analytics ever be completely hallucination-free?
Yes — but only with a deterministic architecture where the AI generates a database query rather than an answer. Probabilistic systems (LLMs) cannot be made hallucination-free through guardrails alone. The best published mitigation stacks still carry a roughly 4% residual error rate (Stanford, 2024). A system where the AI generates the query and the database generates the result has no hallucination vector, because the AI never produces data values.
Does a hallucination-free system still use a language model?
Yes. Deterministic AI systems like AutoQL use language models — but for a fundamentally different task. The language model handles translation: converting natural language into query language. The model never generates data values. It generates the instructions to retrieve them. This preserves the usability of natural language interaction while removing the accuracy risk of answer generation.
Which industries need hallucination-free analytics most?
Any industry where a wrong number drives a wrong decision with material consequences. Financial services (where incorrect figures can trigger regulatory non-compliance or misallocated capital), logistics and supply chain (where erroneous data affects procurement and fulfillment), healthcare (where data errors affect clinical and operational decisions), and defense and government (where auditability is both a compliance requirement and a procurement condition). For deeper coverage of industry-specific use cases, see Chata.ai's solutions pages.
How do I evaluate whether an AI analytics tool is hallucination-free?
The most direct test is also the simplest: ask the same question twice and verify that the answers are identical. Then ask the system to show you exactly how it derived that answer. A deterministic system will produce the same result consistently and will surface the underlying query on demand. A probabilistic system may vary on repeated queries and will not be able to produce a verifiable derivation. If a vendor can't show you the query live in the product, they're generating answers — not querying data.
The Most Direct Test
A slide deck doesn't tell you whether an AI analytics system hallucinates. A whitepaper doesn't either.
The most reliable evaluation is operational: ask the same question twice. Check that the answers match exactly. Then ask the system to show you, right now, in the live product, exactly how it derived that result.
Request a technical demo of AutoQL and see the audit trail live in the product. Bring the hardest analytical query your team runs today. Ask it twice. Watch what happens.
Topics
See How Chata.ai Helps Teams Act Faster
Hallucination-Free AI Analytics Tools: Is It Possible and How Does It Work?
Published
5 min read
Topics:
Reliable AI
Table of Contents
Every AI vendor claims accuracy. Is truly hallucination-free AI analytics actually achievable — or just a marketing promise?
The industry's answer to this has been more guardrails. Better prompts. Smarter validators. However, these approaches treat a symptom, not the disease. The hallucination problem in data analytics isn't a tuning problem — it's an architectural one.
This post explains why hallucination is baked into how most AI analytics tools are built, what a genuinely hallucination-free system looks like under the hood, and what to look for when you're evaluating platforms.
A Stanford RegLab study found that leading legal-AI RAG tools, built by major vendors, still hallucinated in 17–33% of queries — a pattern that shows up whenever RAG is treated as a hallucination "fix" rather than a risk-reducer, regardless of domain.
Why Do AI Analytics Tools Hallucinate?
The short answer: because they were never designed to do math. They were designed to generate text.
Large Language Models are probabilistic next-token predictors. Given a sequence of text, they predict what word is most likely to come next — based on patterns in their training data. This works extraordinarily well for summarization, drafting, and conversation. It is a fundamental liability for data analytics.
When you ask an LLM a data question, it doesn't query your database. It generates a string of text that looks like an answer to a data question. The number it returns is the most statistically plausible number to appear in that context — not a value retrieved from your actual data.
This is the "confident wrong answer" failure mode. The model doesn't know it's wrong. It has no mechanism for knowing. It is doing exactly what it was built to do: generate plausible-sounding output.
This failure mode is especially dangerous in analytics because the outputs are numbers, and numbers look authoritative. A VP of Finance doesn't scrutinize a revenue figure the way they'd scrutinize a paragraph of prose. If the number is formatted correctly and fits the expected range, it gets used.
The IBM Institute for Business Value found that 96% of AI leaders say trustworthy, explainable AI is critical to their organizations — but fewer than half have actually implemented it. That gap exists precisely because the platforms most organizations deploy are probabilistic at their core, and no amount of post-hoc explainability tooling changes what's happening underneath.
The critical distinction is this: in a standard LLM-powered analytics tool, the AI generates the final number. There is no query. There is no audit trail. There is no way to verify where the answer came from — because it didn't come from your data. It came from a model's learned statistical associations.
How Is Deterministic AI Different?
Deterministic AI means the same input always produces the same output. In the context of data analytics, it means the AI never generates a data value — it generates a precise database query, which the database then executes. The data source is the source of truth. The model is a translator, not an oracle.
Here's the architectural difference, side by side:
Probabilistic AI pipeline: Natural language input → LLM → Generated answer (text)
Deterministic AI pipeline: Natural language input → Query language (SQL or equivalent) → Database → Verified result
In the deterministic model, the AI's job is translation: convert the user's natural language question into a precise, executable query. That query is then run against the actual database. The result is a real data value retrieved from a real data source. The model never generates a number. It generates the instructions to retrieve a number.
This distinction matters for three reasons. First, it eliminates the hallucination vector entirely — the database returns whatever the database contains, and databases don't fabricate values. Second, it makes every answer auditable — the generated query is inspectable, shareable, and repeatable. Third, it makes the system consistent — the same question asked twice returns the same answer (assuming the underlying data hasn't changed), which is a property probabilistic systems cannot guarantee.
Deterministic AI in Analytics: When Accuracy Matters Most explores this architectural distinction in depth, including why it's becoming a compliance requirement rather than just a design preference in regulated industries.
This is the architectural principle behind AutoQL — Chata.ai's core analytics engine. AutoQL translates natural language questions into precise database queries, executes them against your connected data sources, and returns verified results. It doesn't generate answers. It generates queries. The distinction is the product.
What to Look for in a Hallucination-Free AI Analytics Platform
Not all AI analytics platforms are architecturally equivalent, and most marketing materials won't tell you which kind you're looking at. The single most important evaluation criterion is whether the system generates the answer (probabilistic) or generates the query (deterministic). Everything else — UI, integrations, visualization options — is secondary to this architectural distinction.
When evaluating a platform, ask these five questions:
Does the system generate a query or an answer? Ask the vendor to show you what the system produces internally before it returns a result.
Is the generated query visible and auditable? A query you can read is a query you can verify. If the system doesn't surface its query to the user, ask why.
Can it connect to your specific database or data warehouse natively? Deterministic AI requires tight schema-level integration. If the system connects to everything generically, it's probably working probabilistically.
Does it maintain consistent output for the same input? Ask the same question twice. The answers should be identical (if the underlying data hasn't changed). Probabilistic systems will often vary.
Can it handle multi-table, cross-system queries without guessing? Complex analytical queries that span multiple tables or systems are where probabilistic systems break down most visibly. Push the system here.
Chata.ai's Natural Language Queries feature is built on this deterministic foundation — every query is traceable, every result is verifiable, and the generated query is surfaced to users with a single click.
The Audit Trail Requirement — Why CTOs Can't Deploy Black Boxes
In regulated industries — financial services, logistics, defense, healthcare — explainability is not a feature request. It is a procurement condition.
A system that cannot explain how it arrived at a number cannot be deployed in environments where that number drives decisions. This is increasingly not a philosophical position but a regulatory one. Deloitte AI Institute (2024) found that 73% of enterprise AI deployments in regulated industries require full decision traceability as a procurement condition.
The "show your work" principle — familiar from school mathematics — has a direct enterprise equivalent: show the query. When Chata.ai's AutoQL returns an answer, the generated query is available to any user with a single click. That query is a complete, human-readable record of exactly how the result was derived: which tables were accessed, which filters were applied, what aggregations were performed. It functions as an audit log by design, not as an afterthought.
This satisfies several distinct stakeholder concerns that typically surface during enterprise procurement. InfoSec teams can verify that the system is querying only the data it's authorized to access. Legal and compliance teams can demonstrate to auditors how any given figure was derived. Data architects can review query logic to ensure it aligns with business definitions and data governance policies.
The alternative — deploying a system that generates answers without generating queries — means accepting that some percentage of decisions in your organization will be made on fabricated data, with no mechanism to identify which ones. In a 250-query workday at a 4% error rate, that's 10 decisions per day made on hallucinated figures. Over a fiscal quarter, that's potentially hundreds of compounding errors with no audit trail to surface them.
For teams building on the AutoQL architecture, Chata.ai's Architecture & Deployment page covers how the query generation and execution pipeline is structured, and how it integrates with existing data governance frameworks.
What Independent Research Says
Third-party validation matters when a vendor is making strong accuracy claims. The Info-Tech Research Group / SoftwareReviews May 2026 evaluation of Chata.ai's architecture provides independent analysis worth noting for buyers in this category.
The evaluation found that Chata.ai's deterministic approach "addresses a fundamental limitation of generative AI in structured data environments — the inability to guarantee output consistency and provide a verifiable audit trail." This mirrors the architectural argument above, from an independent research perspective.
Two additional findings from the evaluation are worth surfacing for enterprise buyers:
Schema-based training, not data-based. Chata.ai's models train on schema structure rather than on live enterprise data. This eliminates the privacy exposure inherent in platforms that train on actual organizational data — a distinction that matters significantly for regulated industries and for organizations subject to data residency requirements.
CPU-based inference. Chata.ai's deterministic inference runs on CPU rather than GPU. This removes the cost curve that makes LLM-based analytics tools prohibitively expensive at enterprise scale — where query volume can run into the millions per month.
FAQ
Can AI analytics ever be completely hallucination-free?
Yes — but only with a deterministic architecture where the AI generates a database query rather than an answer. Probabilistic systems (LLMs) cannot be made hallucination-free through guardrails alone. The best published mitigation stacks still carry a roughly 4% residual error rate (Stanford, 2024). A system where the AI generates the query and the database generates the result has no hallucination vector, because the AI never produces data values.
Does a hallucination-free system still use a language model?
Yes. Deterministic AI systems like AutoQL use language models — but for a fundamentally different task. The language model handles translation: converting natural language into query language. The model never generates data values. It generates the instructions to retrieve them. This preserves the usability of natural language interaction while removing the accuracy risk of answer generation.
Which industries need hallucination-free analytics most?
Any industry where a wrong number drives a wrong decision with material consequences. Financial services (where incorrect figures can trigger regulatory non-compliance or misallocated capital), logistics and supply chain (where erroneous data affects procurement and fulfillment), healthcare (where data errors affect clinical and operational decisions), and defense and government (where auditability is both a compliance requirement and a procurement condition). For deeper coverage of industry-specific use cases, see Chata.ai's solutions pages.
How do I evaluate whether an AI analytics tool is hallucination-free?
The most direct test is also the simplest: ask the same question twice and verify that the answers are identical. Then ask the system to show you exactly how it derived that answer. A deterministic system will produce the same result consistently and will surface the underlying query on demand. A probabilistic system may vary on repeated queries and will not be able to produce a verifiable derivation. If a vendor can't show you the query live in the product, they're generating answers — not querying data.
The Most Direct Test
A slide deck doesn't tell you whether an AI analytics system hallucinates. A whitepaper doesn't either.
The most reliable evaluation is operational: ask the same question twice. Check that the answers match exactly. Then ask the system to show you, right now, in the live product, exactly how it derived that result.
Request a technical demo of AutoQL and see the audit trail live in the product. Bring the hardest analytical query your team runs today. Ask it twice. Watch what happens.
More Updates



